Entries Tagged 'ruby on rails' ↓
December 8th, 2008 — passenger, ruby on rails, tips and tricks
I’ve just recently set up my rails development environment to be managed by Passenger, and I have to say I like being able to type in real URL’s for my domains and not have to manually start my sites.
However, having formerly done my development by first running “script/server” and then going to town, I miss having the log output handy for whenever I blow something up.
If you’ve made the transition to Passenger I imagine you might also feel the same way, so let’s get that back! The easiest way is to use
tail -f log/development.log
Much better! Now we can see the server log output again so it’s easy to view the stack traces for our bugs. However, now that we’re up and running with our super slick hyped-up toy called ‘Passenger’… we’re still having to take just as many steps to get the same results! In fact, typing that command takes longer than script/server used to take.
Well let’s just fix all of our problems in one fell swoop. Add the following to your .bash_login file:
alias go='cd ~/Sites/newcoolsite.com;> log/development.log;mate .;open -a FireFox http://newcoolsite/staff;tail -f log/development.log;'
…where ‘newcoolsite’ is the directory/domain that you’re interested in. Now when we open up our terminal, we just type ‘go’, hit enter, and in about half a second we’ll find the following has happened:
- Our terminal has moved to the proper folder for our site (~Sites/newcoolsite.com)
- The development log is cleared
- TextMate opened our code
- FireFox opened our site (http://newcoolsite/)
- Our terminal started monitoring the server log output
Much better! However there’s still one thing bugging me. We used to just hit Ctrl+C then Up and Enter to restart script/server. It was a very quick and easy way to restart the server and keep our terminal window showing us the activity that we want to see. At this point we still have to type
Ctrl+C
touch tmp/restart.txt
tail -f log/development.log
Unacceptable!! We can easily remedy this situation. Just add a new line to our .bash_login file resulting in the following:
alias go='cd ~/Sites/newcoolsite.com;> log/development.log;mate .;open -a FireFox http://newcoolsite/staff;tail -f log/development.log;'
alias rs='> log/development.log;touch tmp/restart.txt;tail -f log/development.log;'
Now we just hit Ctrl+C, then rs to restart the server and resume our server log monitoring.
Very smooth and painless. Happy coding!
July 1st, 2008 — association proxy, ruby on rails, tips and tricks
I just hit a real mean snag today trying to put an expectation on a model and it didn’t get caught like it should. This is something I do all the time so I knew I wasn’t just making a basic typo. Here’s what my setup looked like:
The model
def purchase
send_shipping_notice
end
def send_shipping_notice
puts "hi"
end
In my spec/test
def given_bought_on(date)
wp = @order.product
puts wp.inspect
wp.should_receive(:send_shipping_notice)
wp.purchase
end
The output
#<Product id: 270, owner_id: 270, name: 'thing'>
hi
1)
Spec::Mocks::MockExpectationError in 'Product should purchase'
Mock 'Product' expected :send_shipping_notice with (any args) once, but received it 0 times
./spec/models/product_spec.rb:21:in `given_bought_on'
script/spec:4:
So as you can see, I put an expectation on the wp variable, and verify it gets called by seeing ‘Hi’ get printed. However the expectation totally gets overlooked and my test framework complains that it never happened.
The catch is that the wp in my test and the web_page self inside the model are two different models. So the expectation is on a different model. Calling .object_id or .inspect on either one will affirm (or rather lie) to you that they’re the same, but they are not.
This is (as I’m told) well documented in ActiveRecord and is intentional by design. The wp variable is in fact an Association Proxy, not the WebPage I think it is. It just lies to you outright so you think it’s a WebPage.
My solution, while rather a hack, is the only thing I know to get my spec to pass:
def given_bought_on(date)
wp = Product.find(@order.product_id)
puts wp.inspect
wp.should_receive(:send_shipping_notice)
wp.purchase
@order.reload
end
Now it grabs the model directly and there’s no confusion.
June 24th, 2008 — pagination, ruby on rails, tips and tricks
I want my list of data to be paginated by letters. The will_paginate plugin certainly gives excellent pagination if all you want is “prev 1 2 3 .. 6 next” kind of pagination.
However what if you’re looking for entries that start with the letter H and you have no idea if that’s page 4 or page 42? You’re probably wanting something more like “# A B C D…” pagination.
I did some googling and found people speaking of solutions for “A B C D…” but in my case, not all of my entries start with letters! If you have something like media titles in your data set, having an entry start with a number is perfectly normal. Some might even start with special characters! Some people suggest having an ‘All’ option, but if you need pagination, it’s probably because you have enough data that showing all options at once is a very bad idea.
Here’s my solution:
First I make a helper function for my options that’ll be cached permanently.
def letter_options
$letter_options_list ||= ['#'].concat(("A".."Z").to_a)
end
Here’s my index action in my controller:
@letter = params[:letter].blank? ? 'a' : params[:letter]
if params[:letter] == '#'
@data = Model.find(:all, :conditions => ["title REGEXP ?",
"^[^a-z]"], :order => 'title', :select => "id, title")
else
@data = Model.find(:all, :conditions => ["title LIKE ?",
"#{params[:letter]}%"], :order => 'title', :select => "id, title")
end
Here’s my html
<div class ="pagination">
<% letter_options.each do |letter| %>
<% if params[:letter] == letter %>
<span class="current"><%= letter %></span>
<% else %>
<%= link_to letter, staff_games_path(:letter => letter)%>
<% end %>
<% end %>
</div>
There we go! Now the # will pull up all entries where the first character is not a letter.
March 31st, 2008 — plaintext, ruby on rails, stories, tips and tricks, webrat
Building off of my last post on Stories, I’d like to show you some improvements I was able to make with the help of WebRat.
You can install WebRat using:
script/plugin install http://svn.eastmedia.net/public/plugins/webrat/
I got the inspiration from Ben Mabey at ‘ben.send :blog’ which illustrates an approach to stories that is unbelievably easy to pick up. He also provides source code to the example that he’s built so that you can play with it. Very cool!
I snagged that source myself and started playing with it, and added a lot of functionality of my own that I found useful. The real cool thing is that the ONLY application specific code I have is this:
# user_steps.rb
steps_for(:user) do
Given("that $actor is not logged in") do |actor|
get "/sessions/destroy"
response.should be_redirect
flash[:notice].should == "You have been logged out."
#fails here even though in the next request it will pass
#controller.should_not be_logged_in
end
Then("$actor $should be logged in") do |actor, should|
controller.send(shouldify(should), be_logged_in)
end
end
# navigation_steps.rb
def path_from_descriptive_name(page_name)
case page_name
when "home"
""
when "signup"
"users/new"
when "login"
"sessions/new"
else
"#{page_name}"
end
end
With that, and the generic application-independent helper methods that also live in my steps directory, I can write the following story:
Story: Making posts
As a visitor
I want to be a member
So that I can make posts
Scenario: Glenn creates a new account
Given that Glenn is not logged in
And there are some number of users
And no user with login 'Glenn' exists
When he goes to the signup page
And fills in Login with 'Glenn'
And fills in Email with 'glenn@glennfu.com'
And fills in Password with 'blah'
And fills in Confirm Password with 'blah'
And clicks the 'Sign up' button
Then there should be 1 more user
And a user with login 'Glenn' should exist
Scenario: Glenn logs in
GivenScenario Glenn creates a new account
When Glenn goes to the login page
And fills in Login with 'Glenn'
And fills in Password with 'blah'
Then he should be logged in
Scenario: A member makes a post while logged in
GivenScenario Glenn logs in
And there are some number of posts
When he goes to the posts page
And clicks on 'New post'
And fills in Title with 'Woo'
And fills in body with 'Stuff here'
And clicks the 'Create' button
Then there should be 1 more post
And a post with title 'Woo' should exist
Scenario: A nice lady makes a post while not logged in
Given that she is not logged in
Then she should not be logged in
Given there are some number of posts
When she goes to the posts page
And clicks on 'New post'
Then she should see the login page
Scenario: An angry visitor should be able to see posts
Given that he is not logged in
When he goes to the posts page
Then he better not f'ing see the login page
Scenario: A visitor should not be able to edit posts
GivenScenario A member makes a post while logged in
And that she is not logged in
When she goes to the posts page
And clicks on 'Edit'
Then she should see the login page
Pretty cool, huh? I was even able to add some personality with the angry visitor Scenario. Notice that I don’t have any steps written about Posts or my PostsController. I don’t need it because I have generic model steps that parse the model from the text in my PlainText instructions. It has all the basics that you need. You interact with forms and links on the top level by name, and then check the results either by text on the page or by finding models.
If you’d like to play with it yourself, I’ve zipped up my stories folder for you to play with.
Download it here!
It also has the old user_story.rb from the previous example. If you have any suggestions for improvements to this or ideas for something else I should do with it, please leave a comment!
My only quirk with this is that if you check the first step in the steps_for(:user) above you’ll see I have a line commented out. It checks for controller.should_not be_logged_in and if I uncomment it, the check fails even though the two above it pass. As you can see in the PlainText, on the very next line I call the very same check and it passes. If you could help me figure out my mistake here I’d really appreciate you leaving a comment with your thoughts!
I hope you find this useful, and if so, be sure to go toss a thank you over to Ben for the inspiration.
February 28th, 2008 — rspec, ruby on rails, time, tips and tricks, world domination
I just recently worked on a project in which I needed to modify what time the Ruby on Rails server thought it was. I was able to change this very easily with the help of court3nay while on #rubyonrails.
def Time.now
Time.parse("2010-02-30", nil)
end
With this I am able to change the server time whenever I want! The system was one in which user interface capabilities changed at different times of the month. Obviously I didn’t want to wait 20 days to see something different!
I placed this code snippet in my config/environments/development.rb file so that everything in my application could access it, and it wouldn’t affect the test or production environments. The only downside to this is that you have to restart the server in order to change the time. Of course, in RoR this takes like 5 seconds so it was no big deal for me.
In my specs I used stuff like
date = "2008-01-01"
Time.stub!(:now).and_return(Time.parse(date))
which of course made it very easy to write effective specs that covered all of my functionality. Thank you RSpec!
Voila, now you too can control time!!
February 20th, 2008 — instance variables, ruby on rails, scope, tips and tricks
I just recently built a rake task in my project where I wanted to loop through a list of Users, queue up some data for each one, then loop back through them again to process the data that had been queued. I didn’t need the data to live for very long, but I needed it for 2 separate requests.
The problem with this is that in Ruby on Rails, instance variables are not persistent across requests. This means their scope is limited to one usage of an object and the next time you call for that object, the variable is gone.
Unfortunately, the only solution I could imagine for my problem without persistent instance variables was to create a massive join table to connect my generated data between Users. Not only would this have been a lot of work, it would have been a big waste considering the data would have only lived for about a minute as the rake task was executed.
I wanted to improve/increase the scope of instance variables, and so my solution was to take advantage of Class Variables.
At the bottom of my User class, I now have the following:
protected
def late_employees
@@late_employees ||= {}
@@late_employees[self] ||= {}
@@late_employees[self]
end
def late_team_members
@@late_team_members ||= {}
@@late_team_members[self] ||= {}
@@late_team_members[self]
end
def clear_late_emails
@@late_employees[self] = {}
@@late_team_members[self] = {}
end
As you can see, each element of the Class Variable hashes are referenced by the current instance. So when I call u.late_employees, it’s always the same across requests until either I call u.clear_late_emails or the server dies.
To use them, just treat them like any normal instance method/variable. Here is an example of how you can do that:
def employee_late(user, days)
if user.manager == self
late_team_members[user] = days
else
late_employees[user] = days
end
end
def has_late_employees?
!(late_employees.empty? and late_team_members.empty?)
end
def send_late_employee_emails
if has_late_employees?
EvaluationNotifier.deliver_late_employee_notification(self)
end
length = late_employees.length + late_team_members.length
clear_late_emails
length
end
Voila, instance variables that are persistent across requests!
February 1st, 2008 — capistrano, dreamhost, ruby on rails, subversion
When I set up my latest application on DreamHost, I had a real pain of a time. Most of the references I found for help were written in 2006 and referred to outdated commands. Since top Google results for “dreamhost capistrano ruby on rails” are mostly no longer adequate, I hope to help out anyone else who finds themselves in my shoes!
I first got good help from this resource at Rubynoob which references the Dreamhost Capistrano Wiki article.
With those two links and a bit of help from me, you should be all set. To make things quick, let me summarize the key points:
- Set up your app with Fast-CGI enabled
- Set up your own RubyGems following this resource
- Also check out this resource for general Ruby on Rails + DreamHost concerns
- “cap –apply-to .” is now “capify”
- Download my deploy.rb file or read from it below for good explanation of what most of the items do.
- Set up your processes as shown below
- Make sure every file in your /script folder has the first line: #!/usr/bin/env ruby
- Make sure every file looking like /public/dispatch* has the first line: #!/usr/bin/env ruby
My deploy.rb file:
# The host where people will access my site
set :application, "test.gamelizard.com"
set :user, "my dreamhost username set to access this project"
set :admin_login, "my admin login name"
set :repository, "http://#{user}@svn.gamelizard.com/rgamelizard/trunk"
# If you aren't deploying to /u/apps/#{application} on the target
# servers (which is the default), you can specify the actual location
# via the :deploy_to variable:
set :deploy_to, "/home/#{admin_login}/#{application}"
# My DreamHost-assigned server
set :domain, "#{admin_login}@ajax.dreamhost.com"
role :app, domain
role :web, domain
role :db, domain, :primary => true
desc "Link shared files"
task :before_symlink do
run "rm -drf #{release_path}/public/bin"
run "ln -s #{shared_path}/bin #{release_path}/public/bin"
end
set :use_sudo, false
set :checkout, "export"
# I used the handy quick tool to set up an SVN repository on DreamHost and this is where it lives
set :svn, "/usr/bin/svn"
set :svn_user, 'my svn username'
set :svn_password, 'my svn password'
set :repository,
Proc.new { "--username #{svn_user} " +
"--password #{svn_password} " +
"http://svn.gamelizard.com/rgamelizard/trunk/" }
desc "Restarting after deployment"
task :after_deploy, :roles => [:app, :db, :web] do
run "touch #{deploy_to}/current/public/dispatch.fcgi"
run "sed 's/# ENV\\[/ENV\\[/g' #{deploy_to}/current/config/environment.rb > #{deploy_to}/current/config/environment.temp"
run "mv #{deploy_to}/current/config/environment.temp #{deploy_to}/current/config/environment.rb"
end
desc "Restarting after rollback"
task :after_rollback, :roles => [:app, :db, :web] do
run "touch #{deploy_to}/current/public/dispatch.fcgi"
end
My script/process/reaper file:
#!/usr/bin/env ruby
require File.dirname(__FILE__) + '/../../config/boot'
require 'commands/process/reaper'
My script/process/spawner file:
#!/usr/bin/env ruby
require File.dirname(__FILE__) + '/../../config/boot'
require 'commands/process/spawner'
The permissions in the script/process folder should look like:
-rwxr-xr-x 1 Malohkan staff 108 Jan 7 19:06 reaper
-rwxr-xr-x 1 Malohkan staff 109 Jan 7 19:06 spawner
If they look like “-rwxr-xr-x@” as can happen on a Mac you’ll want to kill the file and re-create it with the same content. I think this happens due to copying files and is representative of the notion that only the current logged-in user can access that file. As a result, when Capistrano deploys the file, it will not have permission to run it.
If you have other issues or concerns that are not addressed here, please leave a comment and I’ll do my best to help further!
If you don’t like the trouble caused by dealing with Ruby on Rails on DreamHost, check out this article for some ideas of good alternatives!
December 28th, 2007 — 2.0.2, ajax, bugs, javascript, ruby on rails
After updating to Ruby on Rails 2.0.2 I ran into a problem where old code stopped working. The Ruby on Rails Weblog talks about new functionality to allow for us to use .html.erb instead of .rhtml and .js.erb instead of .rjs.
However it appears they may have broken something. In my project I have a controller with a ‘join’ method ending with this code:
respond_to do |format|
format.html { render :layout => 'join' }
format.js
end
My problem was that the join.rjs file was not called at all when the join action was called with text/javascript in the header (an AJAX call). Instead, the .html layout would always return.
Interestingly enough, renaming join.rjs to join.js.erb did allow for the file to be returned when I made an AJAX call, but RoR did not format it into Javascript.
My solution was to rename the join.rhtml to join.html.erb. Now the Javascript file gets properly executed with both .rjs and .js.erb.
I’m not sure under what exact conditions this bug pops up, but I know I have many other AJAX calls and many other .rhtml and .rjs files working just fine in other areas of my project. However, until this bug (if it really is a bug) is adequately dealt with, this workaround seems to do just fine.
I’ve posted a bug report here.
Edit: According to this forum post, while the original documentation is misleading, the desired format is .js.rjs. This should also solve this problem.
December 21st, 2007 — ajax, code improvements, inplaceeditor, patches, railscasts, ruby on rails, script.aculo.us
Recently in a project that my brother and I were working on we ran across a problem with the Ajax.InPlaceEditor resulting in the number of rows for the editor being incorrectly determined. Here you can see the area before it’s used:

When I clicked on the edit icon I got:
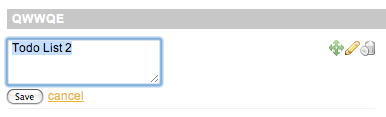
Clearly not what I wanted. After fiddling with all the possible pieces and configurable parameters I finally traced it down to the source and realized there was a bug in the original code:
createEditField: function() {
var text = (this.options.loadTextURL ? this.options.loadingText : this.getText());
if (1 >= this.options.rows && !/\r|\n/.test(this.getText())) {
Looking in the 2nd check of the if statement you see it’s checking for line breaks in “this.getText()”. It should have been checking the “text” variable it had just created above it. Changing that code to:
createEditField: function() {
var text = (this.options.loadTextURL ? this.options.loadingText : this.getText());
if (1 >= this.options.rows && !/\r|\n/.test(text)) {
…fixed the problem! Now when I click my InPlaceEditor I get:

To share my fix I went to the Script.aculo.us page on Submitting Patches but unfortunately their instructions didn’t work right away for me.
Luckily Ryan Bates posted a Railscast called Contributing to Rails that had the right information I needed. Once I had successfully produced my diff file I submitted the patch to the Rails Trac.
Hooray! My first ever patch!
November 27th, 2007 — assert_buggy, code improvements, restful routes, ruby on rails
Yesterday I upgraded my project from 1.2.5 to RC1 of Ruby on Rails 2.0 and had some problems with my routes. During my upgrade process I found a really great post over at assert_buggy called How to upgrade Ruby on Rails Restful routes to 2.0.
Here you’ll find a really handy tool for checking everywhere in your code that you use any paths and allows you to fairly quickly create a hash linking from your old routes to the new correct routes, then run a script to update all of your code with the changes.
Unfortunately for me I had a LOT of custom routes, but I knew a lot of them still worked so I didn’t want to manually try and compare them with the “rake routes” output to see what was out of date.
At the time of this posting the code doesn’t have a way to show me only what’s messed up, and while I know the developer could add some functionality to check which of my routes was not found in a proper way, in the meantime I’ve come up with a cheap hack.
Just change line 22 from:
"#{m}" => ""
to
"#{m}" => "#{m}"
EDIT: The original author implemented my change and now requires no editing in order to use in this manner. Enjoy!
and do steps 3 and 6 which would be:
require 'route_migrator'
RouteMigrator.dump_current_route_methods
RouteMigrator.check_new_routes
and voila you’ll get some helpful output looking something like mine:
"The following new named routes you've specified seem to be not existent"
"home_room_path"
"partitioned_path"
"test_room_report_path"
Now instead of checking all 50+ of my crazy custom routes to figure out which ones don’t go anywhere, I’m given only the 3 from my code that don’t have a proper map.
My sincere thanks go out to assert_buggy!